We all know AI is changing everything, right? It’s powering amazing tools for analysis, automation, and decision-making. But here’s the kicker: AI thrives on data, and a lot of that data is personal. That’s where the EU’s GDPR comes in, and it throws up some serious roadblocks for anyone trying to build AI systems that respect privacy. Let’s break down five of the biggest headaches.
1. Data Minimisation: Less is More, But AI Wants More
GDPR’s big on “less is more” – only collect what you absolutely need. But AI? It’s a data glutton. It wants everything to get accurate. So, we’re stuck trying to reconcile these two opposing forces.

The Real Problem: AI models need a ton of data, which makes it hard to stick to GDPR’s limits. Specifically, when designing machine learning algorithms for tasks like natural language processing or image recognition, the model’s performance directly correlates with the amount of training data. This creates a tension between the need for large datasets and the principle of data minimization. Moreover, how do you stop AI from using data for something other than its original purpose? For instance, data collected for customer service might be repurposed for marketing analytics, which can violate the purpose limitation principle.
And those fancy privacy techniques like differential privacy and federated learning? They’re tough to implement. Differential privacy, while providing strong privacy guarantees, often comes at the cost of reduced model accuracy. Federated learning, which trains models on decentralized data, introduces complexities in managing distributed computations and ensuring data consistency across different devices or servers.
What We Can Do: We need to get smarter about limiting data exposure with things like privacy-enhancing technologies (PETs). This includes techniques like homomorphic encryption, which allows computations on encrypted data, and secure multi-party computation, enabling collaborative analysis without revealing individual data. And using fake, “synthetic” data can help reduce our reliance on real personal info. Synthetic data generation tools are becoming increasingly sophisticated, capable of producing realistic datasets that mimic the statistical properties of real data without containing identifiable information.
2. Explaining the “Black Box”: Transparency Matters
GDPR says people have a right to know how AI decisions affect them. But a lot of AI, especially deep learning, is like a black box. We don’t really know what’s going on inside.
The Real Problem: Think of AI, especially the fancy deep learning stuff, as a really complicated recipe. You throw in a bunch of ingredients (data), and it spits out a result. But we don’t always know how it got there. It’s like a black box – we see what goes in and what comes out, but not the steps in between. This is a big problem because GDPR says people have the right to know why an AI made a decision about them. How do you explain a bunch of complicated math to someone who just wants to know why they were denied a loan? And, companies don’t want to give away their “secret recipe” – the special way their AI works – because it gives them an edge. It’s a tough balancing act: being open enough to follow the law, but not so open that you lose your competitive advantage.
What We Can Do: We need tools that help us peek inside that black box. Think of “explainable AI” (XAI) as a flashlight for AI. Techniques like LIME and SHAP are like little detectives that help us figure out which ingredients (data) were most important in the recipe (decision). LIME gives us a close-up view of why a specific decision was made, like zooming in on a single step in the recipe. SHAP gives us a broader view, showing us which ingredients had the biggest impact overall. We also need regular check-ups, like getting your car inspected.
Independent experts can look at the AI and see if it’s treating everyone fairly. Are there any hidden biases? Is it making decisions that unfairly hurt certain groups of people? These check-ups aren’t just about following the rules; they’re about making sure AI is used ethically and responsibly, and that everyone gets a fair shake. We also need to come up with some clear guidelines, so everyone knows how to explain their AI in a way that’s both helpful and doesn’t reveal too much of their “secret recipe.
3. Data Rights: Access, Erasure, and Moving Data
GDPR gives people a lot of control over their data: they can see it, delete it, or move it. But AI models, especially those trained on personal data, make that a real challenge.
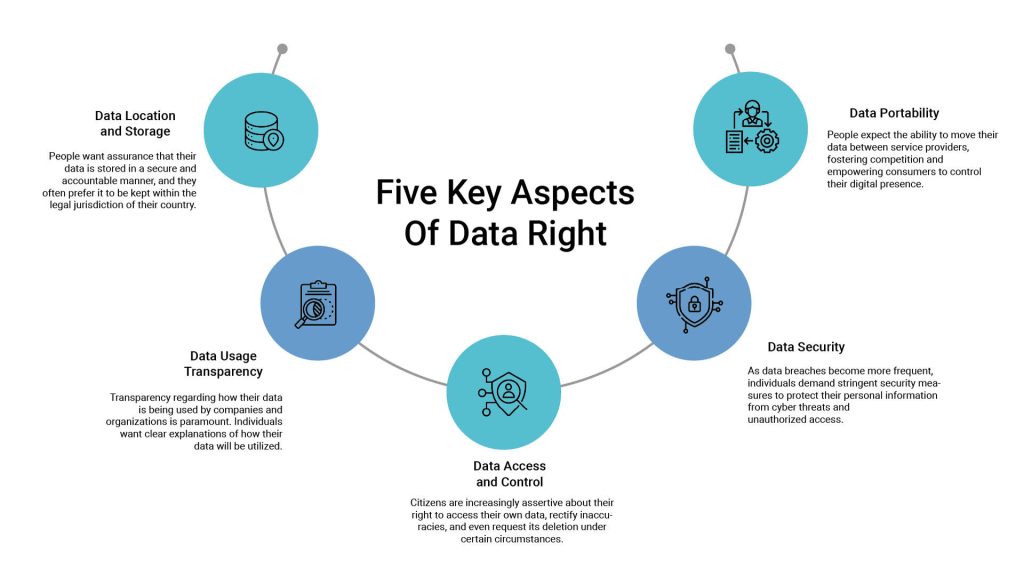
The Real Problem: You can’t just delete data from an AI model like you would from a spreadsheet. AI models learn patterns and relationships from data, and deleting specific data points can affect the model’s overall performance. And moving data around without breaking the system is tricky. Ensuring data portability while maintaining system integrity requires careful planning and implementation. Plus, things like images and voice recordings make it even harder. Unstructured data formats require specialized tools and techniques for data extraction and processing, adding to the complexity of compliance.
What We Can Do: We need to figure out ways to “unlearn” data from models. Machine unlearning techniques, such as retraining models on datasets with removed data points, can help address this issue. And using modular designs that let us remove data without retraining everything can help. Modular AI architectures allow for the isolation and removal of specific components, making it easier to comply with data deletion requests without retraining the entire model.
4. Consent: Getting it Right is Tricky
GDPR often requires explicit consent to use personal data. But AI often relies on data collected without asking directly.

Image Description: An interface showing a consent management platform with user permission settings. Include icons representing anonymization and pseudonymization processes.
The Real Problem: People don’t always understand how their data is being used. Complex AI systems may collect and process data in ways that are not immediately apparent to users. And letting them change their mind later is technically complex. Managing dynamic consent, which allows users to withdraw consent at any time, requires robust data management systems and audit trails. Plus, AI can mix data in ways that blur the lines of consent. AI-driven systems may aggregate data from multiple sources, making it difficult to trace the origin and purpose of each data point, which can lead to consent violations.
What We Can Do: We need good consent management platforms (CMPs) to keep track of permissions. CMPs can provide detailed information about data usage and allow users to easily manage their consent preferences. And designing AI that keeps personal info separate from the analysis data is key. Techniques like data anonymization and pseudonymization can help protect personal information while allowing for meaningful data analysis.
5. Moving Data Across Borders: EU Rules are Strict
AI systems often need to move data across countries. But GDPR has strict rules about moving data outside the EU.
The Real Problem: We need to make sure data flows comply with EU laws. This involves adhering to strict data transfer mechanisms, such as Standard Contractual Clauses (SCCs) and Binding Corporate Rules (BCRs). And figuring out how to keep data local while keeping AI efficient is tough. Data localization requirements can limit the ability to leverage global datasets and cloud-based AI services. Plus, the whole Schrems II thing has made things even more complicated. The Schrems II ruling invalidated the EU-US Privacy Shield, leading to increased scrutiny of data transfers to third countries.
What We Can Do: We can use federated learning to keep data local and train models. Federated learning allows models to be trained on decentralized data without transferring the data itself. And we need solid contracts and agreements with international partners. This includes implementing robust data protection agreements and ensuring compliance with relevant data transfer regulations.
Balancing AI innovation with GDPR’s strict rules is a real challenge. We need to build privacy into AI from the start. By understanding these issues and working on solutions, we can use AI ethically and responsibly.

